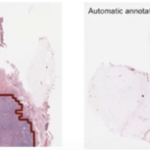
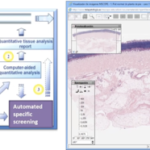
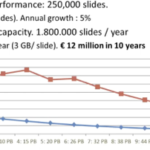
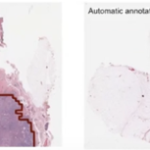
Structured data
- For structured data, the volumes tend to be controllable and an efficient storing system through a relational database was classically enough until recently.
- The data meticulously organized in a Relational Database Management System (RDBMS) can be accessed fast via a Structured Query Language (SQL) enquiry : a concept called vertical scalability which has its limits which is memory dependent (beyond terabytes).
- Also to be efficient, they need to obey the ACID principle:
- Atomicity: only complete operations can update the database
- Consistency: excludes invalid data
- Isolation: operation does not interfere with another
- Durability: an operation can only be done in sequence: that is after the database has updated following the previous operation.
However big data storage with the huge volumes requires a horizontal storage system, and because of the time it takes before we actually work on the data, a safety in storage is required and making several copies is sensible.
Unstructured data
- RDMS cannot be used as the data does not have any purpose when it is collected real time and this is usually big in terms of volume, speed. If there was an organisation, it would indeed be very difficult to change.
- Unstructured data is collected, copied and stored in many servers (often accross the world). This is done as servers have a natural tendency as objects to fail and to be able to retrieve the data, reliability needs to be there. Speed is important but not as much than for vertical scalability systems.
- We will now mention how unstructured data is stored: “Hadoop Distributed File System (DFS)”
- Hadoop Distributed File System (DFS):
- This is the storage system of Big Data, that is unstructured and semi-structured data
- The name comes from the plush toy of Cutting’s son: “Hadoop”. Doug Cutting from the University of Washington developed the system.
- The system functions under the principle of horizontal scalability.
- This means that the data is added on different servers and can be added organically and cheaply:
- thousands of datanodes. There is one “name node” cluster which contains the metadata and is connected and manages access to the other nodes called “slave datanodes”.
- Slave datanodes contain all the data and several copies of it. Replication is important as they have an inherent tendency to fail. While they are operational they send a “heartbeat” to the name node. Failure do do so signals the name node to take out that data storage node and to adapt this to the future distribution of the data.
- When datanodes fail, it doesn’t matter, the individual size of each one is only 64 megabytes, so its replicates compensate for it. However a namenode required a backup to restore it should it fail.
- This means that the data is added on different servers and can be added organically and cheaply:
Reference: Big Data: A very short introduction by Dawn E. Holmes. Oxford University Press, 2017