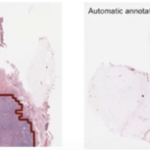
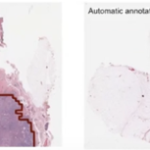
- The adage goes: garbage in garbage out, and this is especially true for machine learning models, since this data sets on which the models are trained and validated, are essential in ensuring the ethical use of the resulting algorithm and poorly trained, poorly representative data sets can introduce biases into the algorithms.
- There are two main types of biases that can exist, although there are many others:
- cases in which the data sources themselves don’t reflect the true epidemiology within a given demographic. And so one example, population data bias by under diagnosis of inflammatory disease in patients of skin and color for instance. If so what are the consequences ?
- If we look outside of medicine, we can see that the result of such bias is likely to be the entrenchment and exacerbation of systemic biases. For example with Amazon’s AI program that was aimed at supporting hiring decisions, HR decisions, by applying algorithms to application files. And in hindsight, it’s obvious that training of program on data fraught with systemic gender and other biases was only going to lead to a model that perpetuated the same.
- cases where algorithms are trained on data and datasets, which are not representative. For example an interesting study (2020), found a striking geographic representation skew in AI studies with most of the studies and the population represented coming from just a few states.
- Alternatively, we can consider what happens when a data set doesn’t contain enough members of the given demographic. For example facial recognition software performs exceedingly well on white men, but poorly on young women of skin and color. From a technological performance perspective and also fundamental reasons of equity and justice, the research community, academia industry, regulatory bodies, need to take steps to ensure that machine learning training data mirror the populations for which the algorithms will be used.
- cases in which the data sources themselves don’t reflect the true epidemiology within a given demographic. And so one example, population data bias by under diagnosis of inflammatory disease in patients of skin and color for instance. If so what are the consequences ?
- And so one approach exemplified by the “All of Us Precision Medicine Research” cohort in the United States, is to actually proactively fund the development of more representative datasets that can be used for training and validation.
- Could we think of a parallel of this research initiative in our field in dermatology, by developing a more representative dataset of patients, for example, who may be traditionally underrepresented.
Justin Ko, MD. Ethical Considerations in AI. 8th World Congress of Teledermatology, Skin Imaging and AI in Skin diseases – November 2020