Backpropagation is the name of the technique.
- This technique is the hallmark of supervised learning, that is when the data is labelled.
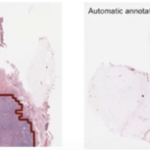
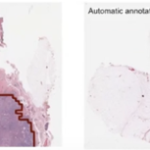
- The data provided reaches the output layer of a neural network. The result is compared with the correct labelled data. The difference is computed as a value called the loss function.
- The difference of the value is then fed back to the hidden layers where the weights are tweaked between the nodes.
- Hopefully after a few epochs compared with the labelled results, the model becomes more accurate ! ((an epoch is one passage of the whole dataset through the artificial neural network)
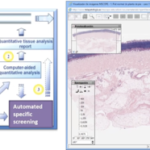
In order to learn and measure results, three types of datasets are used:
- Training set: this is the most in terms of quantity. Basically this is the raw data which is fed to the algorithm through the input layer. This data is not labelled.
- Validation set: It is often a subset of the training set and is important for the learning process. This data is labelled so that the results can be compared with the data passed through. It is not however enough for the creation of the model: see overfitting and undercutting below.
- Test set: this set is completely separate from the validation set and training set. It is used to test the accuracy of the created prototype to make predictions.
- The test set consists of a non-labelled dataset which is replicated with the answers.
- By passing the unlabelled test set, predictions can be made and compared with the answers (labelled test set)